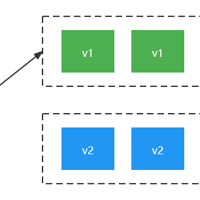
此前没有了解过LoRA模型,可以能是由于接触的比较偏底层,最近接触所以查了一些资料并记录下来,接下来让我们来了解下LoRA模型是什么,并且它有哪些作用。首先LoRA我称之为模型,实际这是个很主观的叫法,LoRA(Low-...
此前没有了解过LoRA模型,可以能是由于接触的比较偏底层,最近接触所以查了一些资料并记录下来,接下来让我们来了解下LoRA模型是什么,并且它有哪些作用。首先LoRA我称之为模型,实际这是个很主观的叫法,LoRA(Low-...
CUDA驱动程序提供向后兼容的API。因此,新的NVIDIA驱动程序将始终与旧的CUDA工具包一起工作。这里记录了CUDA的这种行为。然而,每个CUDA工具包都需要最低版本的NVIDIA驱动程序。因此,当使用诸如NVID...
计算能力(CC)定义了每个NVIDIA GPU架构的硬件特性和支持的指令。在下表中查找您的GPU的计算能力。对于传统GPU,请参考传统CUDA GPU计算能力。有些卡没有找到,但是你可以通过命令查询卡的计算力,使用如下命...
之前我们有学习过nccl的部署和ncc-test工具的使用,我们可以查看之前的笔记:https://sulao.cn/post/988今天我们就根据nccl官网文档https://docs.nvidia.com/deep...
我们通常看到发布的开源模型都会有写10b,17b,100b等等这些数字,这些都是指的模型参数规模,现在大模型参数从原来的亿级暴增至几百亿,这些由于现在gpu性能的大幅提升以及应用对模型的性能需求,导致了参数规模爆发式增长...
在Linux系统中,load和idle是衡量CPU忙闲状态的两个重要指标,它们从不同的角度反映了CPU的使用情况。1.loadload是指系统在特定时间间隔内运行的平均进程数。它反映了CPU的工作负荷,具体数值可以从/p...
模型内部的结构和组成因类型而异,但以常见的深度学习模型(如神经网络)为例,其核心组成部分和机制可以总结如下:1.基本结构组件输入层(Input Layer):接收原始数据(如文本、图像、数值),并将其转换为模型可处理的格...
大模型通常指的大语言模型,这个大主要体现在规模上,一般指的参数规模和包含更复杂的神经网络架构,目前模型主要有包括Transformer、卷积神经网络(CNN)和循环神经网络(RNN)这几种模型架构。一般模型训练是为了通过...
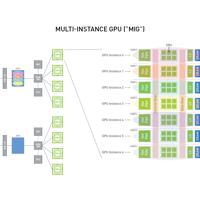
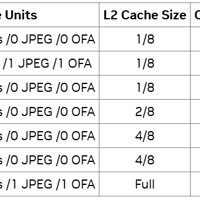
MIG通过虚拟地将单个物理GPU划分为更小的独立实例,这项技术涉及GPU虚拟化,GPU的资源,包括CUDA内核和内存,被分配到不同的实例。这些实例彼此隔离,确保在一个实例上运行的任务不会干扰其他实例。使用MIG,每个实例...
我们在k8s使用英伟达GPU时想让POD自动挂载我们需要部署nvidia-device-plugin组件,如何部署使用可以查看我之前的笔记:https://sulao.cn/post/975英伟达的device plug...
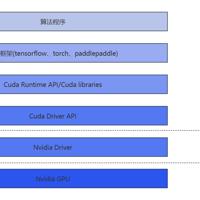
目前市面上有很多GPU共享技术,在GPU共享的模式下,在用户态共享和内核态进行共享是不一样的,根据以下视图,越往底层,共享对用户的影响越小,安全性也能对应提升。下面我就来简单介绍下目前GPU共享的一些技术1.CUDA劫持...
在 vGPU 模式下,GPU 上的内存是静态分区的,但计算能力在共享 GPU 的 VM 之间分时共享。在这种模式下,当虚拟机在 GPU 上运行时,它“拥有” GPU 的所有计算能力,但只能访问其共享的 GPU 内存。在 ...
神经网络的训练梯度下降法学习率: 步长更大= 学习率更高误差函数不断减小。如果训练数据过多, 无法一次性将所有数据送入计算。现将数据分成几个部分: batch分多个 batch , 逐一送入计算训练Epoch一个epoc...
静态库和动态库最本质的区别就是:该库是否被编译进目标(程序)内部。静态(函数)库一般扩展名为(.a或.lib),这类的函数库通常扩展名为libxxx.a或xxx.lib 。这类库在编译的时候会直接整合到目标程序中,所以利...
服务注册中心本质上是为了解耦服务提供者和服务消费者。对于任何一个微服务,原则上都应存在或者支持多个提供者,这是由微服务的分布式属性决定的。更进一步,为了支持弹性扩缩容特性,一个微服务的提供者的数量和分布往往是动态变化的,...
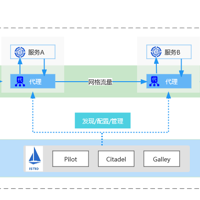
微服务会将应用程序分解为多个较小的服务组件。与传统的一体化(Monolithic)架构相比,微服务架构将每个微服务视为独立的实体与模块,从根本上有助于简化代码和相关基础架构的维护。应用程序的每个微服务都可以编写在不同的技...
由于经常要用,记录下windows原版下载地址和安装过程,还有序列号windows商业版下载地址:ed2k://|file|cn_windows_10_business_editions_version_1909_x86...
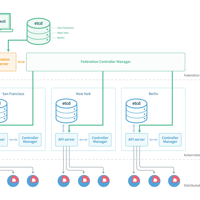
集群联邦 Federation 的目的是实现单一集群统一管理多个kubernetes集群的机制。这些集群可以是跨地域的,跨云厂商的或者是用户内部自建集群。一旦集群建立联邦后,就可以使用集群 Federation AP...