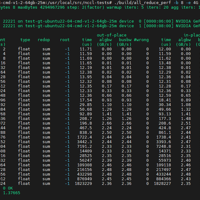
nvbandwidth是一款用于 NVIDIA 图形处理器带宽测量的工具,nvbandwidth 会使用复制引擎或内核复制方法来测量不同链路上各种 memcpy 模式的带宽。nvbandwidth 会报告您系统当前的测量...
nvbandwidth是一款用于 NVIDIA 图形处理器带宽测量的工具,nvbandwidth 会使用复制引擎或内核复制方法来测量不同链路上各种 memcpy 模式的带宽。nvbandwidth 会报告您系统当前的测量...

cublasMatmulBench这个工具非官方渠道的工具,但是从nvidia github上的资料信息来看,应该是某些渠道获取的一个工具,可以在环境中正常使用。今天就来介绍怎么使用这个工具,用法比较简单,主要是针对GM...
Tensorflow在启动的时候会占用所有显存,然后自行对显存进行管理,这是tensorflow的显存管理机制,他可以申请到连续的显存地址然后进行分配,这样对显存的使用更高效,在实际使用中,由于显存资源比较紧张,所以可以...
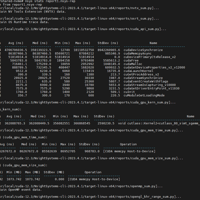
NVIDIA Nsight™ Systems 是一款系统级性能分析工具,旨在实现应用算法的可视化,找出程序中最值得优化的"瓶颈",并进行调整以跨任意数量或大小的 CPU 和 GPU (从大型服务器到最小的系统级芯片 (S...
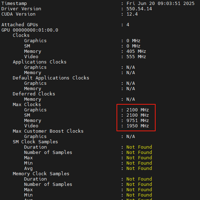
gpu在电源功率不足,温度过高或者在长期高负载或者是驱动程序影响的情况下会降频,那么我们可以通过锁频来固定gpu的频率,当然这种方式也不能解决高温和电源功率不足的问题,我们这里只是了解下如何锁频,操作比较简单。我们首先通...
CUDA驱动程序提供向后兼容的API。因此,新的NVIDIA驱动程序将始终与旧的CUDA工具包一起工作。这里记录了CUDA的这种行为。然而,每个CUDA工具包都需要最低版本的NVIDIA驱动程序。因此,当使用诸如NVID...
计算能力(CC)定义了每个NVIDIA GPU架构的硬件特性和支持的指令。在下表中查找您的GPU的计算能力。对于传统GPU,请参考传统CUDA GPU计算能力。有些卡没有找到,但是你可以通过命令查询卡的计算力,使用如下命...
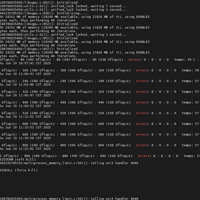
gpu-burn是一款GPU压力测试工具,今天就来介绍下如何安装和使用gpu-burn。首先我们我先去拉取源码包,地址是:https://github.com/wilicc/gpu-burn,目前也支持部分操作系统的二进...
我们通常看到发布的开源模型都会有写10b,17b,100b等等这些数字,这些都是指的模型参数规模,现在大模型参数从原来的亿级暴增至几百亿,这些由于现在gpu性能的大幅提升以及应用对模型的性能需求,导致了参数规模爆发式增长...
在维护算力集群的时候有时候需要统计集群环境中使用GPU卡的POD列表,那么我们经常使用的话这里写了一个脚本方便查询和罗列出这些POD,脚本中主要使用subprocess模块来获取kubectl命令返回的结果,所以执行脚本...
NCCL Tests是一个开源的测试套件,由NVIDIA开发并维护,目的是为了帮助开发者更好地理解和利用NCCL的功能。它提供了多种并发和消息传递模式的基准测试,以评估多GPU间的通信效率,并且支持各种CUDA和MPI环...
日常在一些程序中进行GPU调用,这些cuda程序异常崩溃的时候,有时会遇到掉卡掉驱动、没有进程但是显存被占用的情况,这个时候我们可以通过以下命令来尝试进行处理。如果是掉卡的话可以使用lspci查看下主板上还能否检测到GP...
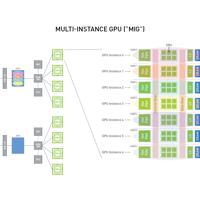
MIG通过虚拟地将单个物理GPU划分为更小的独立实例,这项技术涉及GPU虚拟化,GPU的资源,包括CUDA内核和内存,被分配到不同的实例。这些实例彼此隔离,确保在一个实例上运行的任务不会干扰其他实例。使用MIG,每个实例...
我们在k8s使用英伟达GPU时想让POD自动挂载我们需要部署nvidia-device-plugin组件,如何部署使用可以查看我之前的笔记:https://sulao.cn/post/975英伟达的device plug...
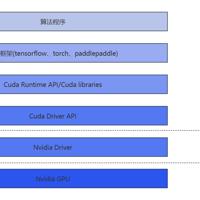
目前市面上有很多GPU共享技术,在GPU共享的模式下,在用户态共享和内核态进行共享是不一样的,根据以下视图,越往底层,共享对用户的影响越小,安全性也能对应提升。下面我就来简单介绍下目前GPU共享的一些技术1.CUDA劫持...
在 vGPU 模式下,GPU 上的内存是静态分区的,但计算能力在共享 GPU 的 VM 之间分时共享。在这种模式下,当虚拟机在 GPU 上运行时,它“拥有” GPU 的所有计算能力,但只能访问其共享的 GPU 内存。在 ...