k8s的安装可以查看我之前的笔记ubuntu安装kvmcentos6安装kvmkVM存储1.资源池的管理kvm默认存储位置是/var/lib/libvirt/images/我们同时也可以创建自定义资源池创建存储资源存储目...
k8s的安装可以查看我之前的笔记ubuntu安装kvmcentos6安装kvmkVM存储1.资源池的管理kvm默认存储位置是/var/lib/libvirt/images/我们同时也可以创建自定义资源池创建存储资源存储目...
整个部署过程花了四五天终于部署好了,操作过程记录下,其实只差一步一直没找到相关资料,所以搞了这么多天,再做一遍估计也就2-3小时就能弄好建议安装kvm宿主机使用ubuntu20.04,省去了配置vifo的麻烦,20.04...
在一套集群里面通常我们都有统一网卡名字的需求,方便进行安装调试和管理那么修改网卡名有两种方式1.临时修改网卡名,不太推荐这种方式这种方式修改的网卡名只是临时的,重启够失效,已在centos和ubuntu上做过测试首先do...

之前安装了一个较老版本的显卡驱动,然后执行nvidia-smi命令发现不能识别显卡名字,然后进行卸载./NVIDIA-Linux-x86_64-xxx.run --uninstall用上述命令一般都能卸载完,但是再安装的...
kvm配置虚拟机一般有几种模式,一般使用桥接和NAT两种模式NAT模式:NAT模式会创建一个网关接口,然后虚拟机配置和这个网口同样地址的IP即可通过宿主机上网,但是外部无法访问虚拟机桥接模式:可以KVM看作为物理网络上的...
Cockpit 是一个免费且开源的基于 web 的 Linux 服务器管理工具。并且在 CentOS 8 和 RHEL 8 中,Cockpit 更是成为其默认服务器管理工具通过 Cockpit 提供的友好的 Web 前端...
kvm Linux虚拟机不仅可以通过VNC来登录操作,也可以通过virsh console控制台来登录网上查了些资料都不太行,最后测试出来了,我的虚拟机是ubuntu18.04,宿主机是ubuntu20.04首先检查/e...
在安装了etcd 3.10版本之后,使用etcdctl和etcd交互时需要将api版本设置为3, 默认,为了向后兼容 etcdctl 使用 v2 API 来和 etcd 服务器通讯。为了让 etcdctl 使用 v3 A...
节点亲和性是 Pod 的一种属性,它使 Pod 被吸引到一类特定的节点。 这可能出于一种偏好,也可能是硬性要求。 Taint(污点)则相反,它使节点能够排斥一类特定的 Pod。容忍度(Tolerations)是应用于 P...
现在工作中经常接触pytorch,tensorflow等AI框架,记录下安装注意事项GPU测试方法1.tensorflow可以在https://tensorflow.google.cn/install页面查看安装说明,注...
静态库和动态库最本质的区别就是:该库是否被编译进目标(程序)内部。静态(函数)库一般扩展名为(.a或.lib),这类的函数库通常扩展名为libxxx.a或xxx.lib 。这类库在编译的时候会直接整合到目标程序中,所以利...
pathlib相对于os模块中的path更简洁,同时这个模块也是python内置模块,我们可以直接使用,下面我们来看看使用方法,使用起来也很简单#!/usr/bin/env python3 #coding:utf-8 f...
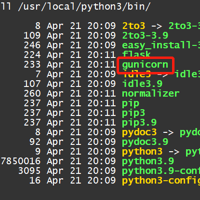
由于centos7中没有安装python3,我们安装python3以后使用pip3安装gunicorn发现无法直接使用gunicorn命令,需要做如下修改才能使用我们先去我们python3安装的目录查看下有没有gunic...
我们这里做一下openssl的升级记录首先我们安装依赖包yum -y install zlib zlib-devel openssl-devel libffi libffi-devel libpcap-devel ncu...
fsck命令被用于检查并且试图修复文件系统中的错误。当文件系统发生错误四化,可用fsck指令尝试加以修复。fsck [选项] 分区设备文件名 -a:自动修复文件系统,不询问任何问题; -A:依照/etc/fstab配置...
Horovod是Uber于2017年发布的一个易于使用的高性能的分布式深度学习训练框架,支持TensorFlow、Keras、PyTorch和Apache MXNet。Horovod的名字来自于俄国传统民间舞蹈,舞者手牵...
k8s中的secret和configmap是为了让POD和配置解耦,使得从集群外部可以想容器内部注入配置信息、环境变量等功能ConfigMap扮演了K8S集群中配置中心的角色,ConfigMap定义了Pod的配置信息,可...
k8s中的亲和性主要是用来做pod的调度策略,可以使pod调度到满足指定条件的节点通常我们还需要给node设置标签,pod通过设置的label标签相关的策略可以使pod关联到对应的label节点上我们先来看下测试环境的n...
今天学习下持久化存储的资源对象StorageClass,这个出现主要是通过 StorageClass 的定义,管理员可以将存储资源定义为某种类型的资源,比如快速存储、慢速存储等,kubernetes根据 StorageC...